-
패스트캠퍼스 환급챌린지 50일차 미션 (3월 21일) : 30개 프로젝트로 끝내는 추천시스템 구현 초격차 패키지 강의 후기2024년 패스트 캠퍼스 챌린지 2024. 3. 21. 20:48
강의 내용 Review
📍배운내용📍
- Self Supervised Learning
- 종류(Generative, Contrastive )
👉강의내용👈
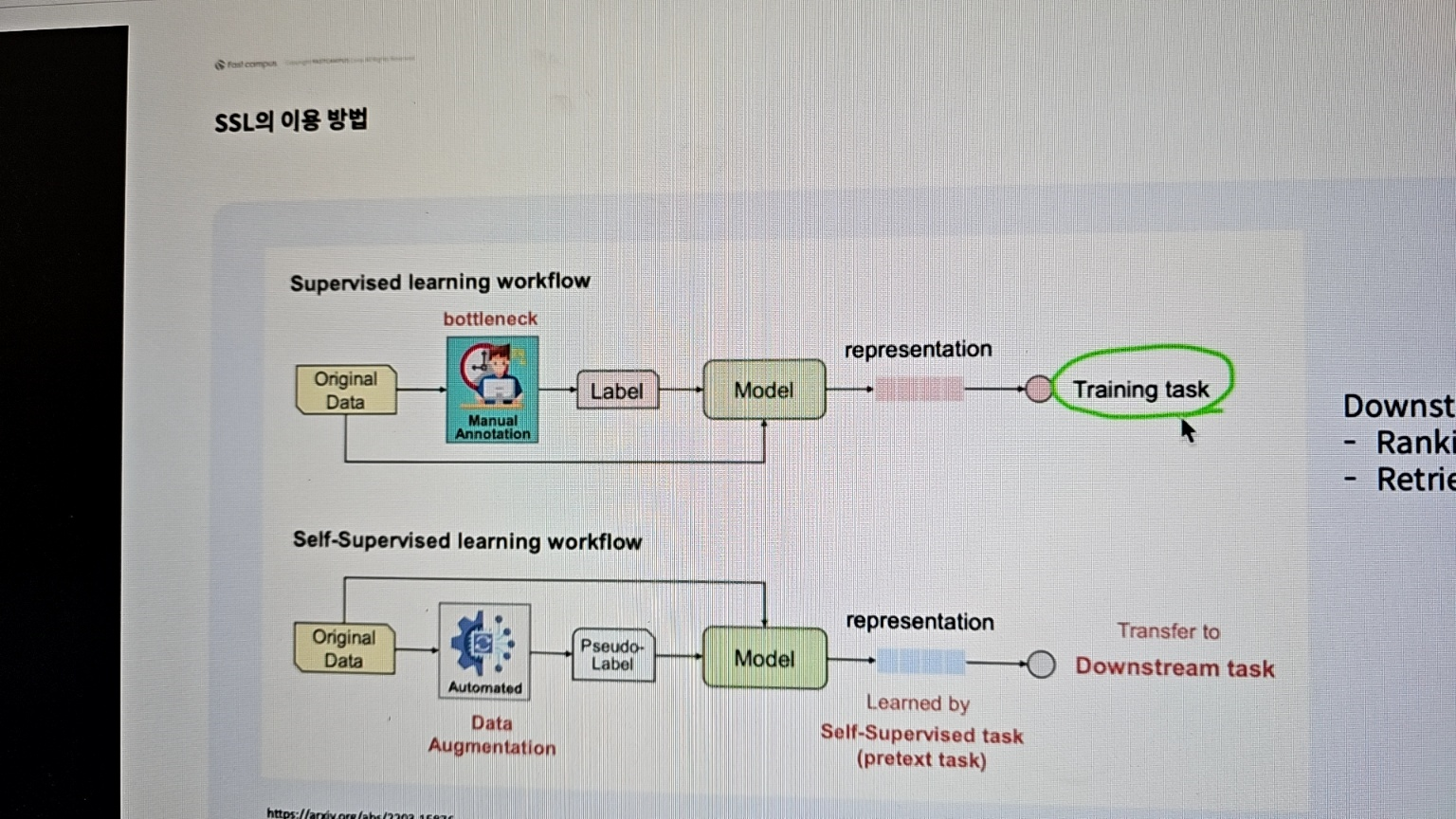
Self Supervised learning
- 임베딩: 숫자가 아닌것을 벡터로 나타내는 것 , 숫자로 나타내는 것을 의미함
- 임베딩은 표현학습에 속함, Retieval -> ANN, Ranking -> Feature
- 임베딩은 압축, 데이터를 벡터로 잘 나타내게 됨
- 레이블이 없거나 제한적인 모델을 학습시키는 방법
- 데이터를 입력받고 입력 받은 데이터로부터 레이블을 자동으로 생성하고 레이블을 학습에 사용함
- 레이블이 있는 데이터가 귀함, 학습을 한다음 트랜스퍼러닝을 해서 다운스트림 태스크에 적용함
- 임베딩을 학습하는 표현 학습의 하나
- 표현 학습은 적절한 임베딩을 배우는 것을 의미함, 세미 지도 학습: 레이블이 없는 데이터로 부터 좋은 임베딩을 배우는 것
- BERT나 GPT같은 NLP에서 혁신적인 성과를 보임
Self Supervised learning 종류
- 지도 학습이랑 비교하면 원레데이터와 레이블을 넣어서 이루고자하는 목표를 학습하는데 이때 표현들을 배움
- SSL는 데이터 증강을 통해 유사한 레이블을 만들고 표현을 먼저 배움, 미리 배운 태스크를 통해서 다운스트림에 적용함
- 추천에서는 랭킹과 조회가 있음
- 수도 레이블을 만드는 방법은 Generative 방법과 Constract 방법이 있음
- Generative 방법: 원본 데이터를 조금 망가트리고 복원을 시킴, 복원이 된것이 원본가 얼마나 비슷한지 로스 계산
- BERT는 pre training으로 임베딩을 만들고 간단한 모델로 fine-tuning 을 했더니 좋은성능 보임
- 원본데이터를 파괴하고 데이터를 재 생산함 -> Masking, 순서로 다음 단어 예측함 -> prediction
- 레이블이 없는데서 가상 레이블을 만들어서 학습함
- 시퀀셜 추천에서 NLP를 사용하는데 레이블을 주지는 않고 아이템의 시퀀스를 줌 그것을 통해 word2vec학습
- BERT4REC 사용자의 구매, 기록, 평가, 클릭을 나열하고 마스킹을해서 맞추도록 학습함
- Contrastive 방법: 데이터를 강해서 두개로 만들고 각각 증강한 데이터를 넣어서 동일하게 나오게 함
- Tow-tower에서 피처를 다양하게 만들어서 피처를 다르게 증강해서 유사도 로스를 계산함, share는 모델을 그대로 공유해서 쓴것을 의미함
- 증강하는 방법은 mask과 drop out을 씀: 피처를 완전히 쪼개서 함, 각 임베딩이 얼마나 비슷한지 로스계산
- 몇가지 피처를 빼는 것을 drop out이라고함
- 그래프 에서는 노드나 , 엣지, 특정부분을 빼서 데이터 증강을 함
- 각자 다른 방법으로 증강을하고 증강된것이 유사하게 하도록 함
- Joint Training : 함께 학습함, 임베딩을 배우고 SSL과 ranking을 한번에 학습함
공부사진

50일차 후기
열심히 듣자 !
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다.
'2024년 패스트 캠퍼스 챌린지' 카테고리의 다른 글