2024년 패스트 캠퍼스 챌린지
패스트캠퍼스 환급챌린지 26일차 미션 (2월 26일) : 30개 프로젝트로 끝내는 추천시스템 구현 초격차 패키지 강의 후기
조이쓰
2024. 2. 26. 16:15
강의 내용 Review
📍배운내용📍
- GNN 오버뷰
- Deepwalk 방법
👉강의내용👈
GNN 오버뷰
- 딥러닝은 개체가 갖는 표현 정보를 구하는 것이였음, 단어, 이미지, 문장
- 높은 차원의 데이터를 저차원에 함축시켜서 의미 정보를 잘 담아 낼수있는 덴스 한 표현을 얻는 접근
- GNN에서도 그래프를 구성하는 노드를 임베딩하는 표현 학습 기법 있음
- 그래프의 단점: 입력형태가 다름, 정형화 된 형식이 아님, non 유클리드 한 방법, 인접행렬은 노드의 수가 틀어남에 따라서 행렬계산에 load가 커짐
- 1) permutaion invariant: 노드의 순서를 섞으면 기존의 ML은 안됨
- 2) 순서를 섞더라도 의미, 즉 벡터가 변하지 않도록 하는 것이 보장 되지 않음
- 위 두가지 문제점을 해결할수있는 방법 노드를 dense한 표현, 벡터로 만듦
- 분류, 예측같은 원하는 태스크를 수행하기 위해서 노드를 수치 벡터로 만들어아함
- 연결정보를 반영한 벡터를 만들려면? 인접행렬 사용
- 행렬이 너무 커지면 메모리에 올릴수없고 쪼개야함
- 위치 정보를 하나로 만들어서 이것으로 머신러닝 다운스트림 수행
- 노드를 벡터로 만드는법
- 고차원의에서 non유클리드 정보를 유지하면서 저차원의 벡터개체에 임베딩
- 1) 인코더 정의: 인코딩 펑션 결정
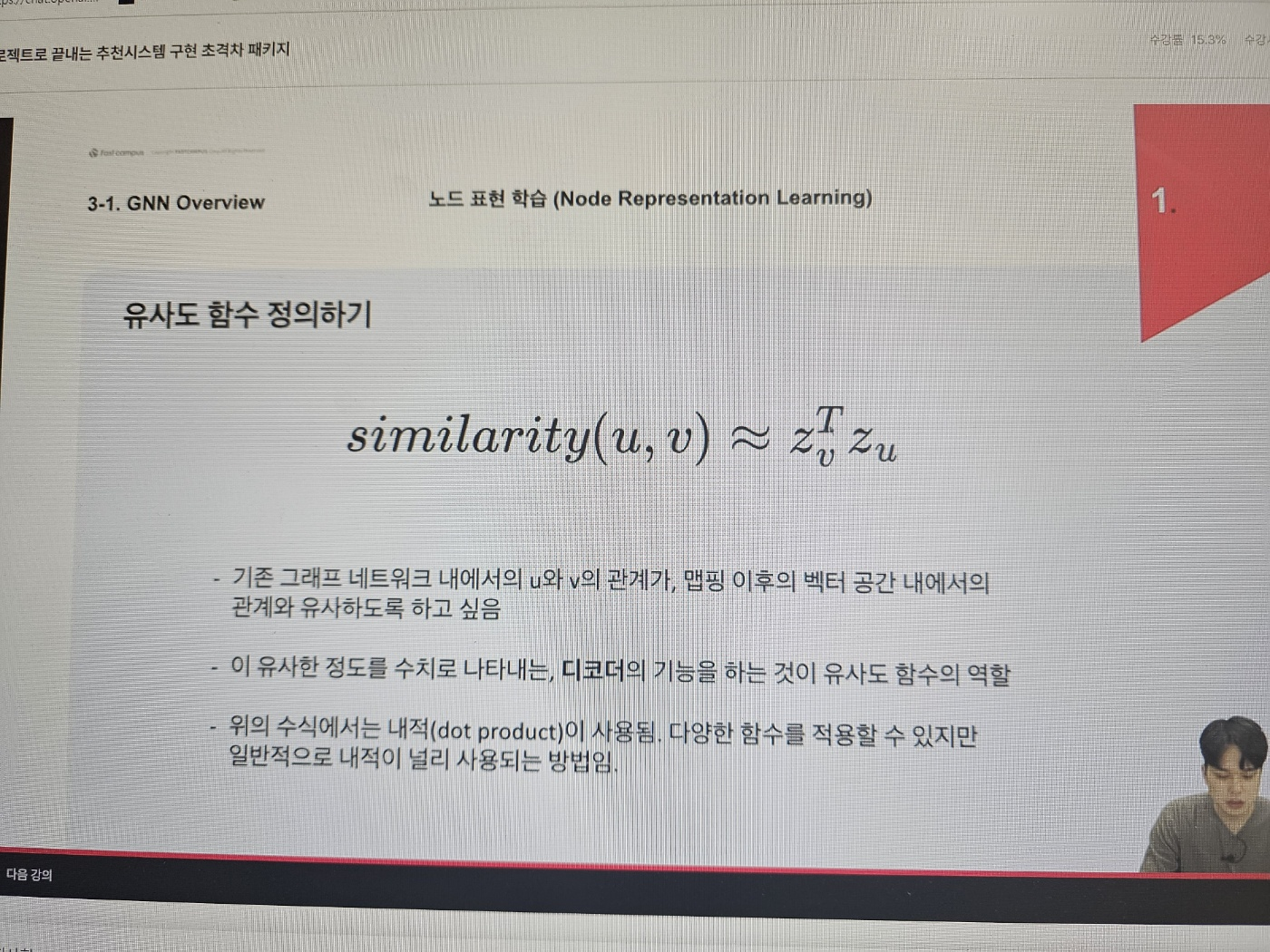
- 2) 유사도 정의: 의미상 비슷한 노드가 가까운 위치를 갖도록
- 3) 파라미터 최적화: 손실값을 통해 파라미터를 의미값을 반영하도록 최저화
- 그래프 노드의 표현학습은 인코더 구조정의하고 손실 정의하고 손실최적화 하는 과정
- 인코더: shallow embedding
- 얕은 임베딩: 하나의 노드마다 하나의 칼럼 할당됨, look up 으로 죄회 될수 있는, 의미 관계를 잘 반영할수있게 임베딩모델 학습 함
Deepwalk 방법
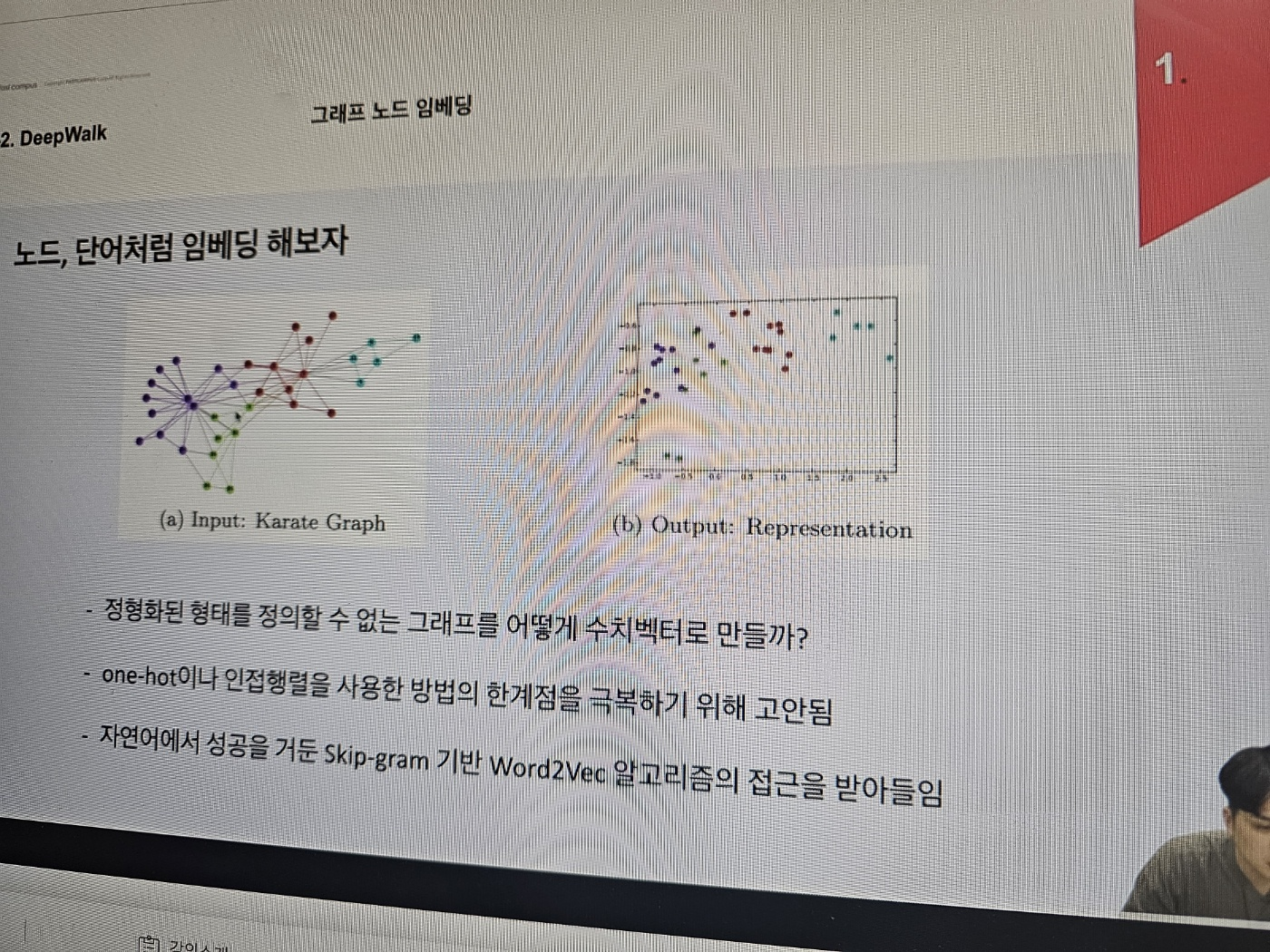
- 인풋으로 들어간 Karqate graph를 2차원 표현으로 임베딩을 하면 잘 분류가됨
- sparse한 형태로 성능이 떨어지는 데 skip gram 가반의 word2vec에 방법 으로 동기를 얻음
- 랜덤워크는 확률적인 방법으로 중요도 구함
- word2vec은 분포가설이 핵심
- 노드에서도 랜덤워크로 시퀀스를 만들면 자연어처럼 처리 할수있지 않을까?
- 스킵그램이 주워지면 윈도우 사이즈에 따라서 발견될수있는 가능성이 높은 애들을 예측, 이 예측과정에서 노드 임베딩 구함
- 딥워크는 유의미한 임베딩 값을 구했다는 점에서 유의미
- 임베딩을 얕게 하는데 노드가 많아질수록 파라미터가 커짐
- 노드간 공유하는 파라미터를 정보를 의존적으로 만드는 것도 중요함
- 한번도 본적없는 노드는 임베딩을 못구함: transductive함 , 귀납적으로 추론 불가능 함
- transductive learning: 전이적 학습, 이미 관측된 인스턴스 필요
- inductive learning : 학습셋으로 부터 특정 함수를 학습해서 일반화 된 추론 수행
공부사진
26일차 후기
생각보다 진도가 잘 안나간다.ㅠ
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다.